블룸버그 프로페셔널 서비스 2018년 4월 11일
이 기사는 ‘2018년, 바이사이드 변화의 해’라는 보고서에서 브루노 두파이어(Bruno Dupire)에 의해 작성되었습니다.
현재 관찰 가능한 데이터(구조화 데이터 및 비구조화 데이터)로부터 미래를 예측하는 일은 재무 분야에서의 주요 프로젝트 중 하나로 금융산업에서는 이를 위해 자연스럽게 머신 러닝을 받아들이고 있다. 이 프로젝트에 성공하기 위해서는 데이터 범위와 취득 방법을 확대하고 일부 오래된 습관은 버릴 필요가 있다.
대부분의 전통적인 재무 데이터는 시장으로부터의 수치 정보 및 증권 가격과 같이 구조화된 형태로 처리되어 왔고, 이를 처리하는 방법은 표준 통계 도구에서 차용하였다. 머신 러닝 및 처리 능력의 진보는 이제 방대한 양의 비구조화 데이터의 처리 및 이해가 가능하다는 것을 의미하며 이는 업계를 변형시킬 잠재적 요인으로 보인다.
데이터 조합의 관련성
금융 시장 참가자들은 세계의 많은 일들이 상호 연결되어 있다는 점과 이러한 상호 작용망을 파악하는 것이 미래 예측 능력을 향상시킨다는 점을 점차적으로 인식하고 있다. 전에는 간과되었던 정보 출처들이 이제는 중요해지고 잠재적 수익성이 있는 데이터의 출처가 되고 있다.
예를 들어 종야등의 세기, 오일 탱크 그림자 및 주차장에 주차된 자동차 수와 같은 위성 이미지는 경제 활동을 평가하는 데 사용될 수 있다. 소셜미디어 및 뉴스 기사를 이용하여 센티먼트를 파악할 수 있는 한편, 신용카드 사용 정보를 통해 소비자 지출 경향을 알아낼 수도 있다.
첫 번째 기술은 가공되지 않은 데이터를 수치로 변형시킨다. 야간 위성 사진으로 불빛의 세기를 측정할 수 있고, 주차장 사진을 분석하여 자동차 대수를 알아내며, 신문이나 트윗의 내용을 극성 지수(polarity index)에 반영하여 긍정적, 부정적 또는 중립적 센티먼트를 만들어낸다.
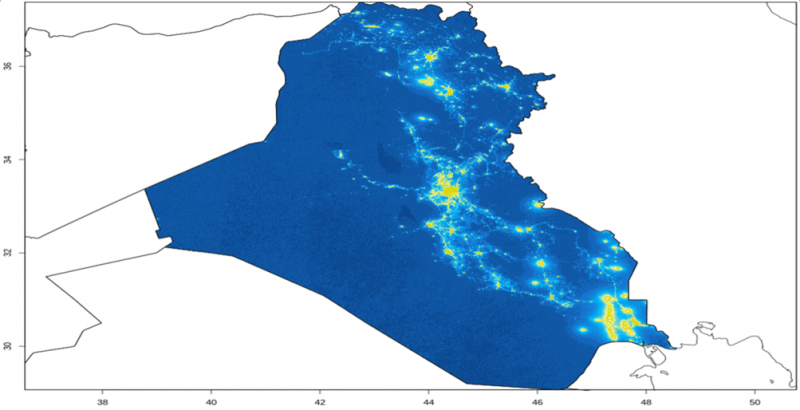
야간 위성 사진: 불빛 세기 척도
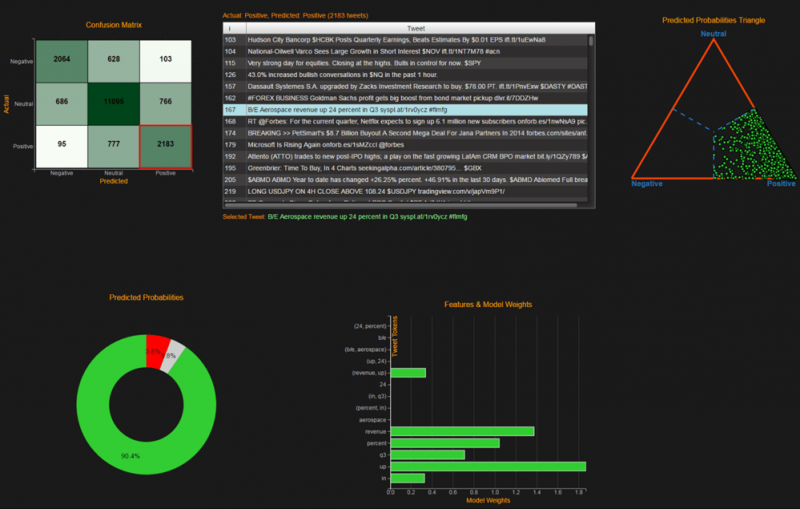
뉴스 기사 또는 트윗: 극성(좋음/나쁨) 지수 (polarity index)
다음 단계는 이 데이터를 예측에 사용하는 것이다. 불빛 세기로 한 국가의 GDP 대비 소비 지수를 예측할 수 있는가? 월마트 주차장을 살펴 실적을 예측할 수 있는가? 한 회사에 대한 소셜 미디어 센티먼트를 통해 해당 회사의 가격 수익성 혹은 변동성을 예측할 수 있는가?
머신 러닝 방법
이용 가능한 데이터의 종류 및 목적에 따라 이용할 수 있는 머신 러닝 방법에는 다양한 형태가 있다. 가장 흔한 방법은 다음과 같다.
• 감독 학습: 여러 관찰 대상(입력)과 이익의 양(출력) 사이의 관계를 학습하려 한다. 특징/라벨이라고도 불리는 두어 개의 입력/출력으로 이루어진 하나의 조합(교육 조합)으로 시작한다. 알고리즘은 파라미터를 조정하여 특징과 라벨 사이의 관계를 알아내려 노력한다. 그런 다음 아직 제시되지 않은 다른 사례 조합(테스트 조합)에 테스트한다. 이 알고리즘은 입력으로부터 출력을 예측하기 위하여 이용할 수 있다.
• 미감독 학습: 미감독 학습에서 시스템은 데이터의 일부 기초 구조를 발견하는데 그 목표를 둔다. 전형적인 예로, 약간의 유사성을 가진 데이터 포인트 그룹을 묶고 찾는 것이다. 다른 예로는 병목현상이 있는 신경망인 오토인코더(autoencoders)를 통한 차원 축소 또는 정보 압축법이 있다.
머신 러닝으로부터 혜택을 볼 수 있는 업무 분야는 무궁무진하다. 다음 표는 블룸버그에서 작업하고 있는 머신 러닝 프로젝트 중 일부를 보여준다.
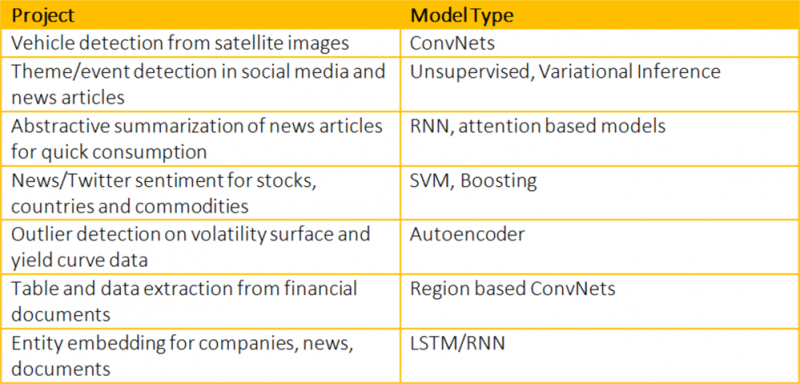
차원수 감축을 위한 오토인코더(Autoencoders)
신경망 사용의 흥미로운 사용 방법 중 하나는 수익률 곡선 또는 변동성 곡면의 차원수를 줄이는 것이다. 수익률 곡선의 경우 전통적으로 주성분 분석(Principal Component Analysis)이 가장 인기 있는 기법이다. 수익률 곡선에서 평행 이동, 기울기 및 뒤틀림은 가장 중요한 세 가지 요소이다.
오토인코더 망은 자신이 생성한 비선형을 최대한 사용할 수 있기 때문에 주성분 분석보다 차원 감축에 더 효과적이다. 오토인코더 망은 입력 정보를 압축된 표현에 정제하여 넣는 병목 현상을 통하여 강제된 초기 입력을 산출로써 재생산하는 데 목적이 있다. 일반적으로 글로벌 행동 양상 및 체제 변화가 있는 경우 오토인코더가 주성분 분석보다 더 잘 작동하는 것으로 관측된다.
알파 창출을 위한 신호를 알아내거나 다양한 시장의 포트폴리오를 구성하는 방법을 배우기 위하여 감독 학습 알고리즘을 사용할 수 있다.
여기에는 다음과 같은 두 가지 예가 있다.
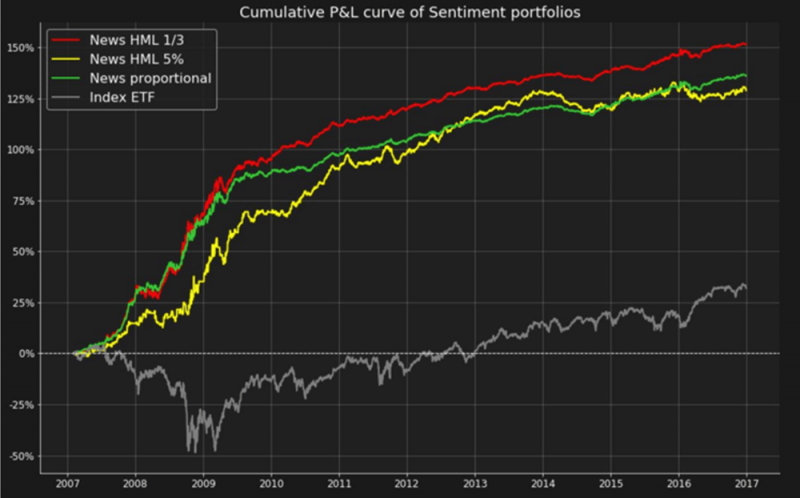
1.센티먼트에 기초한 전략: 트윗이나 뉴스의 텍스트를 분석하여 자동으로 긍정적, 중립적 또는 부정적 센티먼트로 테그된다. 예를 들어, 아래 차트는 이틀 동안 각 15분 단위로 한 주식에 대한 세 가지 종류의 트윗 숫자(MS)를 요약한다.
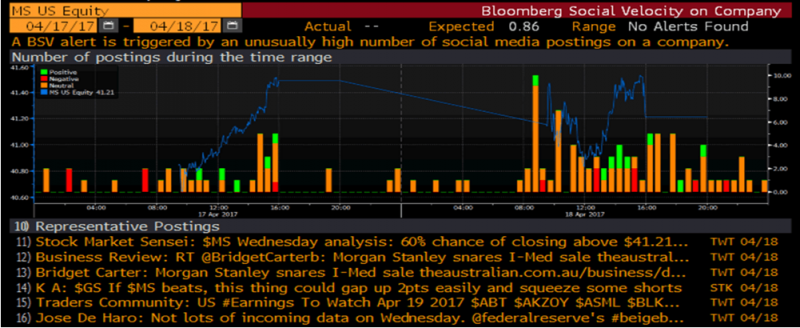
이렇게 처리된 데이터에 대한 분석은 일반적으로 긍정적인 센티먼트의 주식에 대하여는 매수 포지션을, 부정적인 센티먼트의 주식에 대해서는 매도 포지션을 취함으로써 트레이딩 전략을 구성하는 데 이용될 수 있는 트레이딩 신호를 창출한다. 아래 차트는 이런 포트폴리오가 시장보다 상당히 좋은 성과를 내는 것을 보여준다.
2.스마트한 베타 전략: 데이터를 활용하여 트레이딩 전략을 정교하게 만드는 다른 방법은 시장 여건을 나타내는 일련의 특징을 찾아서 요인이나 전략의 목록을 정의하는 것이다. 그런 다음 학습 과업은 특정 시점의 시장 여건과 후속 기간에 적용할 최선의 전략 사이의 연계성을 밝히는 것이다.
시장 여건을 정의하는 데 이용할 수 있는 지표의 예로는 SPX 수익률, VIX 수준, 수익률 곡선 기울기, 신용 스프레드 및 인플레이션이 있다. 전략의 예를 보면, 포트폴리오의 베타와 같은 한 파라미터의 값/순위에 따라 가중치가 주어진 주식이 포함된 포트폴리오, 그리고 파마 프렌치(Fama French) 요인이나 특정 지역 또는 산업 섹터와 관련된 것과 같은 상이한 스마트 베타 펀드가 있다.
감독 학습은 교육 기간 동안 가장 수익성이 좋은 전략과 그에 상응하는 시장 여건 간의 연관성 학습으로 구성된다. 시스템이 이런 연관성을 알아내고 이를 흉내내기 시작하면 샘플 외 기간에 대해 테스트를 실행한다.
아래 차트는 베타 분위수에 따라 동적으로 포트폴리오를 구성하는 방법을 배우는 것의 이점과 동적 포트폴리오가 일반적인 롱-쇼트 포트폴리오의 성과를 어떻게 능가하는가를 보여준다.
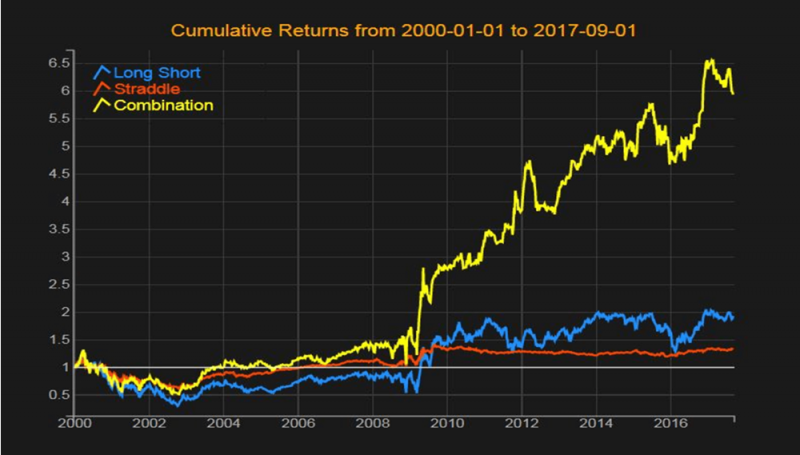
아래 차트는 파마 프렌치 요인 포트폴리오(Fama-French factor portfolios)의 로테이션 전략 구축을 위해 선택한 최적 전략을 보여준다.

새로운 데이터 조합 및 기법의 이용 가능성, 컴퓨팅 파워의 증가는 재무 분야에서의 머신 러닝 응용을 확대하여 왔다. 여전히 초기단계이고 함정도 곳곳에 있으나 신세대 기법, 도구 및 재능이 잠재성을 완전히 펼쳐짐에 따라 그 전망이 밝다.